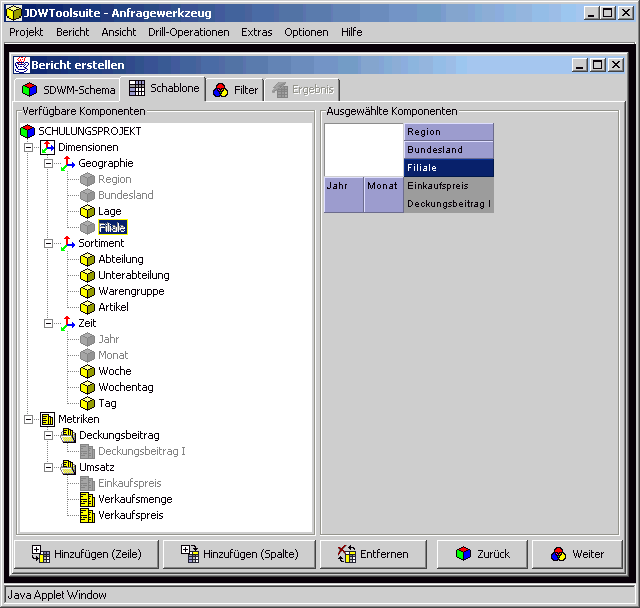
JDW-Toolsuite - Analysewerkzeug

(Version 3.2.1)
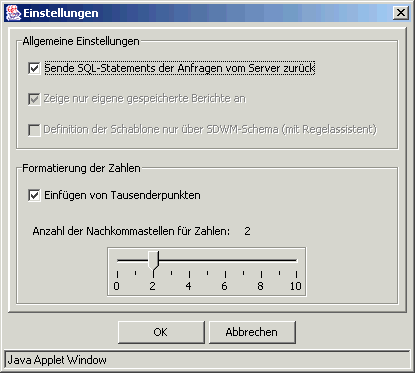
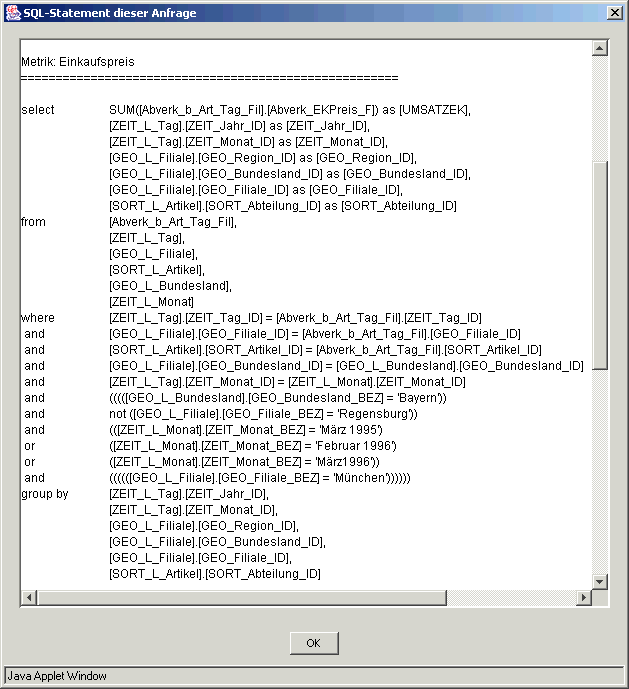
Hinweise
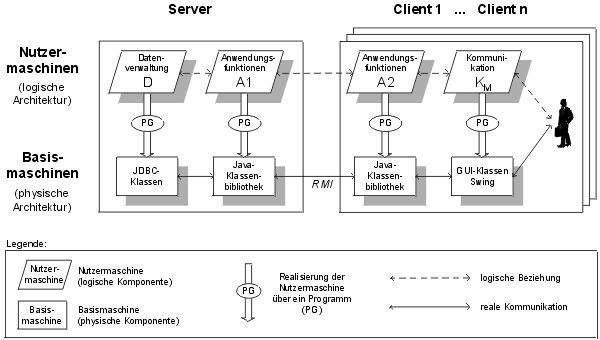
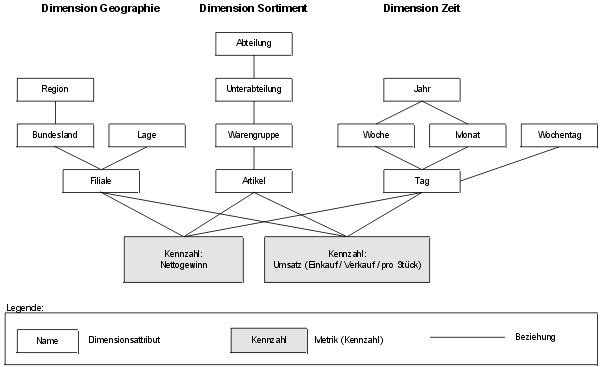
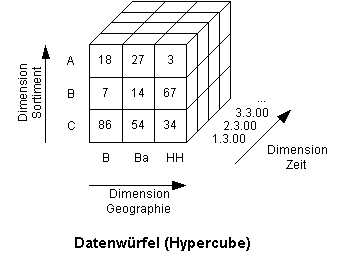
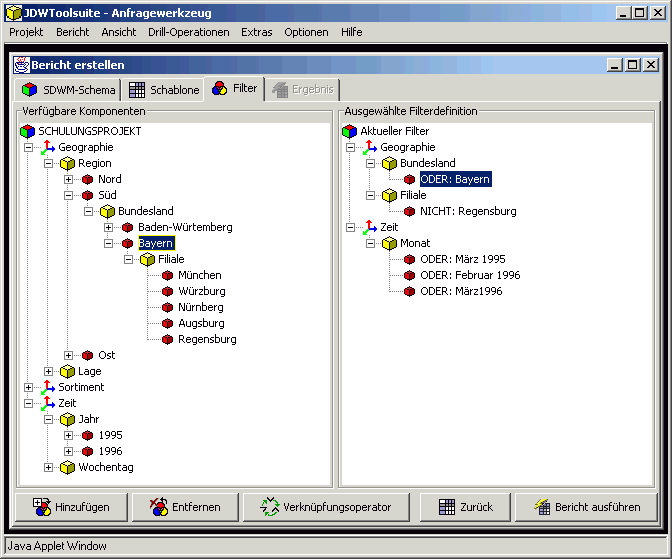
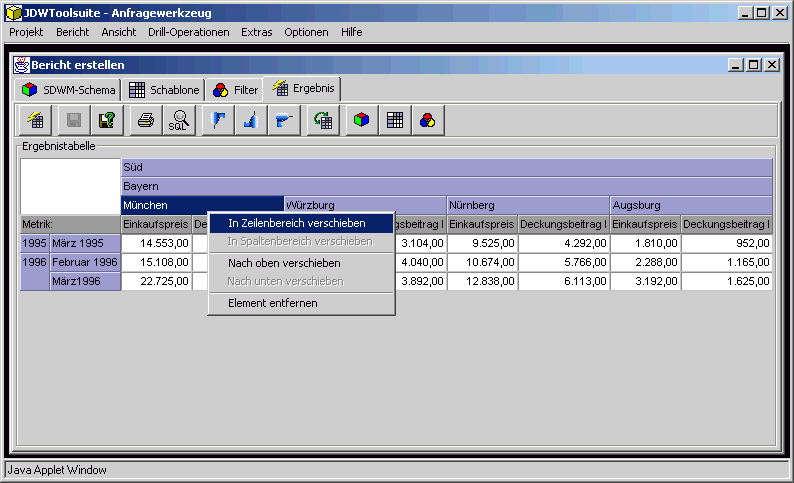
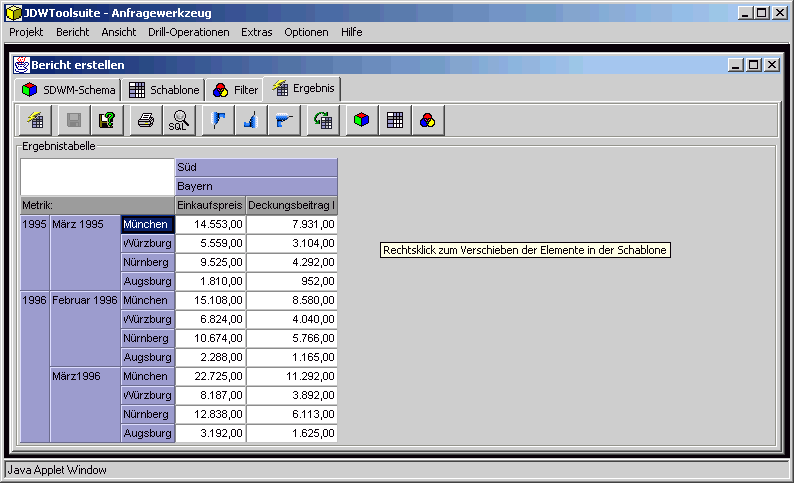
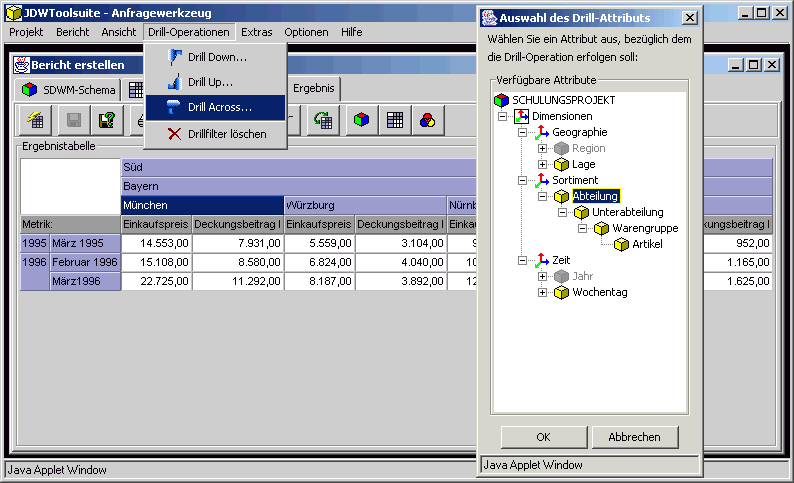
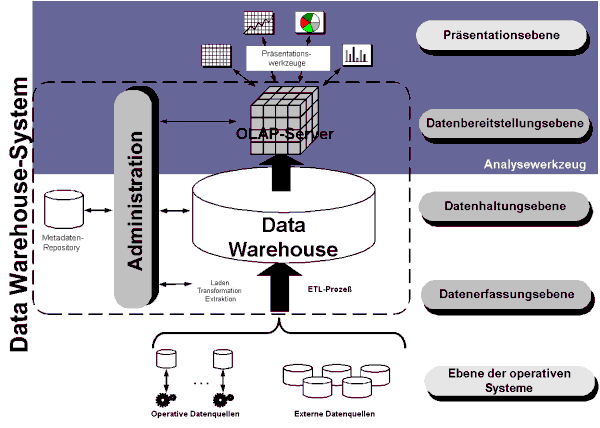
In Abbildung 1 ist die Abgrenzung des Analysewerkzeugs gegenüber der Architektur eines klassischen Data-Warehouse-Systems dargestellt. Das vorliegende Teilprojekt deckt die Ebenen Datenbereitstellung und Präsentation eines Data-Warehouse-Systems ab. Das Tool basiert auf den Daten und den Metadaten der Datenhaltungsebene. Die Schritte Extraktion, Transformation und Laden der Daten aus den operativen Systemen in das Data-Warehouse sind Aufgabe des ETL-Werkzeugs.